yolo各版本学习笔记
yolov1
算法思路
简单来说,便是输入图片,模型处理后得到一些候选框作为预测结果,将可能为物体的候选框展示出来作为检测结果。
将原图片分为$7*7$的格子,每个格子产生两种候选框,代表以此格子为基准预测的物体。 在两种候选框中选择更优的一个。
预测结果
模型输入一个图片,然后输出预测结果。
预测结果为一个$7*7*30$的张量。
这里$7*7$为原图片的长与宽都为7个单位,预测结果的框的长度单位为1。
30个参数中,后20个为预测种类。前10个参数为$(x,y,w,h,c)*2$,其中 c 为 置信度 (confidence),代表此候选框为物体的可能性。
损失函数
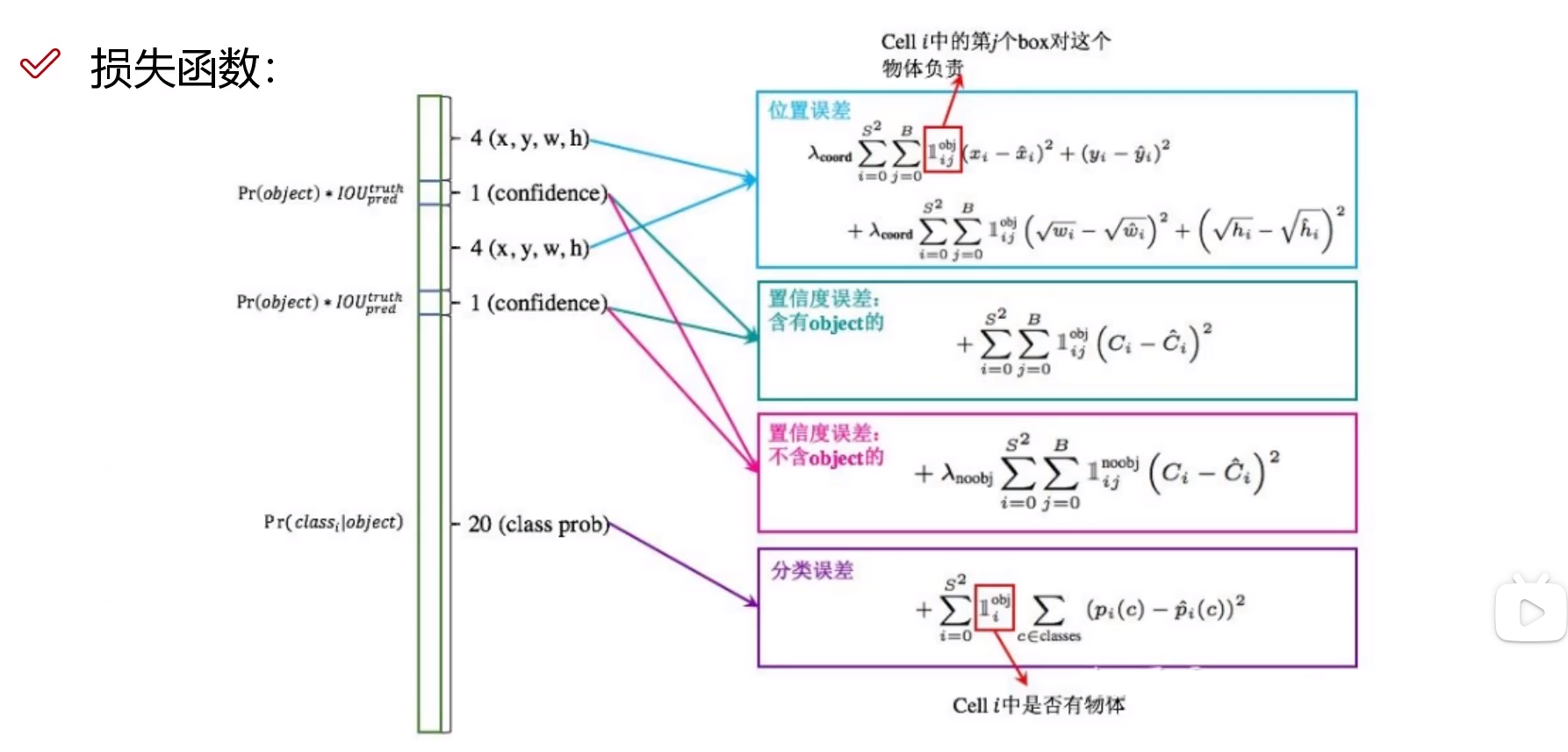
位置误差
对每一个格子预测的两个候选框,选择效果更好的计算损失进行优化。
对于(w,h)两个参数,取根号是为了让参数在更小的时候能更敏感。
置信度误差
分类进行损失计算, 前景比背景更重要一些,背景的权重更小。
分类误差
同常见的分类损失。
NMS
非极大值抑制,即对预测同一物体的多个候选框,取置信度最高的展示。
问题
检测问题
小物体比较难检测到。
重合在一起,或位置较近的,很难同时检测出来。
分类问题
只能做简单的分类,难以对同类别物体进行更细致的分类或多标签识别。
yolov2
Batch Normalization
舍弃Dropout, 卷积后进行 Batch Normalization。
每一层输入都做归一化。
分辨率
v1训练使用 224*224, 测试使用 448*448。
v2额外进行了10次 448*448 训练的微调。
网络结构
使用DarkNet,中间没有FC层。
进行了5次池化。因此实际输入需要能被$2^5=32$整除。
实际输入为 416*416, 实际输出为 13*13。
使用 1*1 卷积核来节省参数。
聚类提取先验框
借鉴faster-rcnn 选择先验比例。
使用K-means对数据集的标注进行聚类(K=5),作为先验框的先验比例。这里K-means聚类中的距离为 $d(box,centroids)=1-IOU(box,centroids)$。
Anchor Box
增加预测的box数量。
mAP并没有提升,但recall值提升。意味着更多的小物体或重合部分被检测出来。
Directed Location Prediction
对结果进行微调。调整结果进行了限制,避免候选框大幅度摆动。
Fine-Grained Features
借鉴VGG的思路,采用小的卷积核。
融合之前的特征,避免小目标丢失。
Multi-Scale
多尺度,可以输入不同的图像尺寸。但是尺寸要能整除32.
yolov3
多scale
分为3个scale,每个scale设置3种候选框。
不再进行最后合并,对不同大小物体的检测各自进行。
scale变换经典方法
图像金字塔方法效率不高,不适合yolo。
用插值的上采样方法,将后面的特征图与前面的特征图融合。
残差连接
残差连接方法让堆叠更多层时效果至少不会变差。
网络设计为多个残差网络块。
网络结构
没有池化和全连接层,全部使用卷积。
下采样通过调整stride实现。
输出结果包括三种:13*13(26*26, 52*52)*3*(4+1+80)。
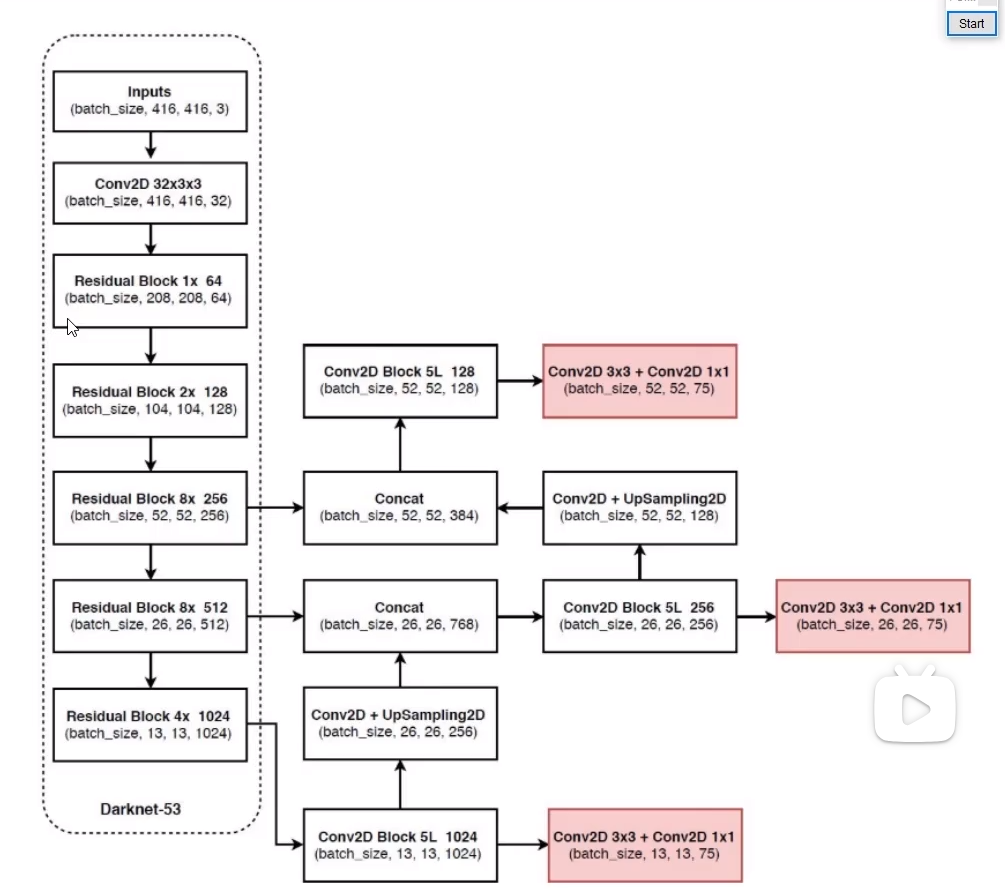
先验框设计
聚类得到9种,按照大小分到3个scale。每个特征图上的格子预测三种先验框。
softmax层替代
使用logistic激活函数完成,可以实现多标签预测。
yolov4
Bag of freebies(BOF)
只增加训练城堡,来明显提高精度,不影响推理速度。
包括数据增强,网络正则化,类别不平衡,损失函数设计等。
数据增强
对图片进行数据增强,包括 Mixup 、 Cutout、 CutMix等方法。
- Mixup:将两张图片进行混合。
- Cutout:将图片的一部分去除。
- CutMix:将图片的一部分替换为另一张图片的相应部分。
- Random Erase:用随机值或平均像素值替换图像部分区域。
- Hide and Seek: 根据概率随机隐藏部分区域。
- Self-adversarial-training(SAT): 引入噪音增加难度。
Mosaic data augmentation
yolov4使用了CutMix方法,将四张图像拼成一张进行训练。
可以间接增加BatchSize,降低训练所需资源。
此外,还使用了 Random Erase、 Hide and Seek、SAT等方法。
DropBlock
随机丢弃一个连续区域,来提高推理难度。
Label Smoothing
将标签平滑一些, 将标签 [0, 1] 修改为 [0.05, 0.95]